- 인덱스란? 데이터의 고유성을 확인하거나 검색 성능을 향상시키기 위해 사용하는 객체로 책에서 목차 부분에 해당한다.
- 인덱스를 사용하는 이유 : 데이터베이스에 저장된 데이터를 빠르게 조회하기 위해서 인덱스를 생성하고 사용하는데 일반적으로 테이블의 전체 데이터 중에서 10~15% 이하의 데이터를 처리하는 경우에 효율적으로 사용이 가능하며 그 이상의 데이터를 처리할 때는 인덱스를 사용하지 않는 것이 더 효율적이다.
- 인덱스의 분류
- 인덱스 컬럼 값의 유일성 : UNIQUE/NON-UNIQUE
- 인덱스를 구성하는 컬럼의 수 : 단일 인덱스/결합 인덱스
- 단일 인덱스
- 인덱스 내에 컬럼이 하나만 존재하는 형태를 의미한다.
- 단일 인덱스의 한계
- 인덱스는 기본적으로 정렬을 하게 되는데 특정 데이터를 찾기 위해서 두 개 이상의 테이블에서 찾을 경우 각 테이블의 인덱스를 따라서 여러 번 찾아야 하기 때문에 매우 비 효율적이다.

- 결합 인덱스
- 인덱스 내에 컬럼이 두 개 이상인 형태를 의미힌다.
- 단일 인덱스에서 한 테이블의 인덱스를 찾고 다시 다른 테이블에서 인덱스에 대한 데이터를 찾는 번거로움을 해소해준다.
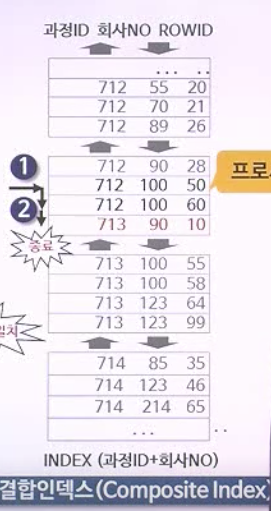
- 위 그림처럼 특정 데이터에 대한 인덱스를 하나로 사용 시에 구조가 간결하게 된다.
- 결합 인덱스 컬럼 선택
- WHERE 절에서 AND 조건으로 자주 결합되어 사용되면서 각각의 분포도보다 두 개 이상의 컬럼이 결합될 때 분포도가 좋아지는 컬럼들
- 다른 테이블과 조인의 연결고리로 자주 사용하는 컬럼들
- 하나 이상의 키 컬럼 조건으로 같은 테이블에서 자주 조회되는 컬럼들
- 결합 인덱스 컬럼 순서 결정
- 결합 인덱스 구성 시에 Equal로 구성된 경우 범위를 제한하면서 데이터를 찾기 때문에 많이 사용 되거나 분포도가 좋은 컬럼을 우선하게 하여 데이터의 범위를 많이 줄일 수 있다.
- 결합 인덱스의 컬럼 순서 결정 조건
- WHERE 절 조건에 많이 사용하는 컬럼 우선
- Equal(=)로 사용 되는 컬럼 우선 : Equal 로 사용하지 않으면 범위 제한으로 사용 되지 않아 데이터를 많이 줄이지 못한다.
- 분포도가 좋은 컬럼 우선
- 자주 이용되는 정렬의 순서로 결정
- 결합 인덱스 사용 방법
- 결합 인덱스 사용결합 인덱스 사용법
EMP_PAY_X1 : (PAY_DAY, PAY_CODE, WORKER_CODE)
-- 결합 인덱스의 첫번째 컬럼만 사용
WHERE PAY_DAY = '202010'
-- 결합 인덱스의 첫번째, 두번째 컬럼 사용
WHERE PAY_DAY = '202010'
AND PAY_CODE = '정기급여'
-- 결합 인덱스 모두 사용
WHERE PAY_DAY = '202010'
AND PAY_CODE = '정기급여'
AND WORKER_CODE = '33139646' - INDEX SKIP SCANNING : 결합 인덱스의 첫번째 컬럼이 WHERE 절에서 제외되어도 두번째 컬럼부터 WHERE의 조건으로 기술된 경우 그 인덱스가 사용된다.
- 결합 인덱스 컬럼에 대한 '=' 의 의미
- 결합 인덱스에서 '='은 데이터의 범위를 제한 조건으로 사용한다.
- 결합 인덱스에서 '='을 사용하지 않으면 체크 조건으로 사용하며, 데이터의 범위가 줄지 않아서 시간이 오래 걸리게 된다.
- 인덱스 매칭률 : 인덱스를 구성한 컬럼들이 얼마나 범위 제한 조건으로 사용되는지 나타내는 비율로 식은 아래와 같다.

- 결합 인덱스를 사용 시 매칭률은 아래와 같다.결합 인덱스 매칭률
EMP_PAY_X1 : (PAY_DAY, PAY_CODE, WORKER_CODE)
-- 결합 인덱스의 첫번째 컬럼만 사용 (매칭률 = 1/3)
WHERE PAY_DAY = '202010'
-- 결합 인덱스의 첫번째, 두번째 컬럼 사용 (매칭률 = 2/3)
WHERE PAY_DAY = '202010'
AND PAY_CODE = '정기급여'
-- 결합 인덱스 모두 사용 (매칭률 = 3/3 -> 1)
WHERE PAY_DAY = '202010'
AND PAY_CODE = '정기급여'
AND WORKER_CODE = '33139646' - 인덱스의 물리적 구성 방식 : B*Tree/BitMap/Cluster
- B*Tree 구조
- 밸런스드 트리 인덱스라고 하며, 가장 많이 사용하는 인덱스 구조이고, 인덱스의 데이터 저장 방식이다.
- 구성 : Root(기준)/Branch(중간)/Leaf(말단) 노드로 구성된다.

- Root 노드는 특정 컬럼으로 인덱스를 생성 시에 컬럼 값들을 정렬하는데 이 때 중간쯤 되는 데이터가 지정된다.
- Branch 노드는 Root를 기준을 가지가 되는 부분으로 Leaf 노드에 연결되어 있어 조회하려는 값이 있는 Leaf 노드까지 도달하기 위해 비교/분기해야 될 값들이 저장된다.
- Leaf 노드는 인덱스의 키가 되는 데이터와 데이터의 물리적 주소인 ROWID 값을 저장한다.
- B*Tree 구조에서는 Leaf 노드단에서 정렬을 한 상태로 존재하게 되는데 해당 구조의 핵심 내용이다.
- BitMap
- 컴퓨터에서 사용하는 최소 단위인 비트 값을 이용하여 컬럼 값을 저장하고, ROWID를 자동으로 생성한다.
- 구성 : 컬럼 값 / START ROWID / END ROWID / BITMAP
- 비트맵 인덱스의 특징
- UNIQUE INDEX는 생성이 불가능하다.
- NULL 값의 저장이 가능하다.
- 최대 30개 컬럼까지 생성이 가능하다.
- 입력될 값의 종류가 적은 컬럼은 B*Tree 인덱스보다 유용하지만, INSERT, UPDATE, DELETE가 빈번히 발생하는 컬럼이면 비트맵 값의 갱신으로 부하가 집중되어 성능저하가 된다.
- Cluster
- 클러스터란? 같은 성질의 컬럼을 가지고 있는 테이블들이나 조인 등을 위해 자주 함께 사용 되는 테이블들을 하나의 그룹으로 묶은 객체를 의미한다.
- 하나의 클러스터로 묶인 테이블들이 공통적으로 갖게 되는 컬럼을 클러스터 키라고 하고 이 클러스터 키로 만들어진 인덱스가 클러스터 인덱스이다.
- 인덱스 선정 절차
- 프로그램 개발에 이용된 모든 테이블에 대해서 Access Path 조사 (Access Path : Where 절부터 Order by 절까지를 의미한다.)
- 인덱스 컬럼 선정 및 분포도 조사 : 분포도가 높은 컬럼을 선정
- Critical Access Path 결정 및 우선 순위 선정 (Critical Access Path : Where 절부터 Order by절까지 조사 시에 자주 사용되는 것을 의미한다.)
- 인덱스 컬럼의 조합 및 순서 결정
- 시험 생성 및 테스트
- 결정된 인덱스를 기준으로 프로그램 반영
- 실제 반영
- 인덱스 생성 및 변경 시 고려할 사항
- 기존 프로그램의 동작에 영향성을 검토한다.
- 필요할 때마다 인덱스 생성으로 인한 인덱스 개수의 증가와 이로 인한 DML 작업의 속도를 검토한다.
- 개별 컬럼의 분포도가 좋지 않을지라도 다른 컬럼과 결합하여 자주 사용 되고, 결합할 경우에 분포도가 양호하다면 결합 인덱스 생성을 긍정적으로 검토한다.
- 인덱스 생성 방법 : CREATE INDEX Index 명 ON Table 명 (Column1, Column2, ...);
- 인덱스 확인 방법 : SELECT * FROM ALL_IND_COLUMNS WHERE TABLE_NAME = 'Table 명';
- 인덱스 삭제 방법 : DROP INDEX Index 명;
- 인덱스 스캔의 원리
- 조건을 만족하는 최초의 인덱스 Row를 찾음
- Access된 인덱스 Row의 ROWID를 이용하여 테이블에 있는 Row를 찾는다.
- 처리 범위가 끝날 때까지 차례대로 다음 인덱스 Row를 찾는다. (2번 반복)
- 인덱스 사용
- 고유 인덱스의 Equal(=) 검색
- 고유 인덱스의 범위(>=, >, <, <=) 검색
- 중복 인덱스의 범위(=, LIKE) 검색 (단, LIKE 검색 시 변수 앞에 '%'가 오는 경우는 사용 못 함)
- OR, IN 조건
- NOT BETWEEN 검색
- 인덱스를 사용하지 말아야 하는 경우는 조건에 의한 처리 범위가 넓어져 분포도가 나빠지는 경우가 있는데, 이 때 인덱스 보다는 FULL TABLE SCAN 으로 처리하여 입출력 시에 여러 개의 데이터를 처리하는게 인덱스 사용하는 것보다 효율적이기 때문이다.
- 인덱스 사용이 불가능한 경우
- 컬럼의 내외부 변형이 발생(External suppressing/Internal suppressing)컬럼의 내외부 변형
EMP_PAY_X1 : (PAY_DAY, PAY_CODE, WORKER_CODE)
-- 결합 인덱스의 첫번째 컬럼에 외부 변형 발생
WHERE TO_NUMBER(PAY_DAY) = 202010
-- 결합 인덱스의 첫번째 컬럼에 내부 변형
WHERE PAY_DAY = 202010
-> TO_NUMBER(PAY_DAY) = 202010 내부 변형됨
AND PAY_CODE = '정기급여' - IS NULL, IS NOT NULL을 사용하여 비교IS NULL, IS NOT NULL 사용
EMP_PAY_X1 : (PAY_DAY, PAY_CODE, WORKER_CODE)
-- 결합 인덱스의 첫번째 컬럼에 IS NULL 사용
WHERE PAY_DAY IS NULL
-- 결합 인덱스의 두번째 컬럼에 IS NOT NULL 사용
WHERE PAY_DAY = '202010'
AND PAY_CODE IS NOT NULL - LIKE 검색 시에 변수 앞에 '%' 사용하여 비교LIKE 검색 시 변수 앞에 '%' 사용
EMP_PAY_X1 : (PAY_DAY, PAY_CODE, WORKER_CODE)
-- 결합 인덱스의 첫번째 컬럼의 변수 앞에 '%' 사용
WHERE PAY_DAY LIKE '%2010'
-- 결합 인덱스의 두번째 컬럼의 변수 앞에 '%' 사용
WHERE PAY_DAY = '202010'
AND PAY_CODE LIKE '%급여' - 여러 컬럼에 OR 조건 사용여러 컬럼에 OR 조건 사용
EMP_PAY_X1 : (PAY_DAY, PAY_CODE, WORKER_CODE)
-- 결합 인덱스의 여러 컬럼에 OR 조건 사용
WHERE PAY_DAY = '202010'
AND (PAY_CODE = '정기급여' OR
WORKER_AGE = '30' OR
WORKER_ADDRESS = '강남구') - 부정형 비교(NOT 연산자 사용)부정형 비교
EMP_PAY_X1 : (PAY_DAY, PAY_CODE, WORKER_CODE)
-- 결합 인덱스의 첫번째 컬럼에 NOT 연산자 사용
WHERE PAY_DAY != '202010'
-- 결합 인덱스의 두번째 컬럼에 NOT 연산자 사용
WHERE PAY_DAY = '202010'
AND PAY_CODE != '정기급여' - 옵티마이저에서 인덱스 선택 절차
- 특정 테이블에 SQL에 주어진 조건으로 사용할 수 있는 인덱스가 두 개 이상인 경우 조건에 가장 적절한 인덱스를 선택한다.
- 옵티마이저의 인덱스 선택시 판단 절차
- 주어진 조건에 대한 각 인덱스 별로 매칭률을 계산하여 매칭률이 높은 인덱스를 우선적으로 선택한다.
- 인덱스 별 매칭률이 같을 경우 인덱스를 구성하는 컬럼의 개수가 많은 인덱스를 우선적으로 선택
- 인덱스 별 매칭률이 같고, 인덱스를 구성하는 컬럼의 개수도 같을 경우는 가장 최근에 생성된 인덱스를 우선적으로 선택한다.





참고도서 : 실전사례로 살펴보는 SQL 튜닝비법